
Red Hat OpenShift Data Science: AI/ML을 위한 클라우드 서비스
더욱 신속하게 지능형 애플리케이션 수용
인공지능(AI), 머신 러닝(ML), 딥러닝(DL)은 수많은 비즈니스와 산업 전반에서 애플리케이션 현대화 노력에 크게 영향을 미치고 있습니다. 다양한 조직은 자체 데이터에서 전략적 가치와 새로운 인사이트를 이끌어내어 지능형 클라우드 네이티브 애플리케이션과 DevOps 방법론 사용을 확장하도록 유도해야 합니다. 이와 같은 새로운 환경은 복잡할 수 있으며 이는 개발자부터 데이터 사이언티스트, 운영 인력까지 모두에게 영향을 미칠 수 있습니다. 기존의 접근 방식으로는 다음과 같은 문제점을 제시할 수 있습니다.
- 시작하는 것이 쉽지 않을 수 있습니다. 빠르게 진화하는 툴과 애플리케이션 서비스를 최신 상태로 일관되게 유지하고, 그래픽 처리 장치(GPU)와 같은 하드웨어 리소스를 프로비저닝하고, 지능형 애플리케이션의 규모를 확장하는 것까지 여러 어려움이 있습니다.
- 널리 사용되는 클라우드 플랫폼은 확장이 가능하며 유용한 통합 환경과 툴셋을 제공하지만, 제한적인 툴체인과 배포 옵션으로 결국 사용자의 유연성을 제한할 수 있습니다.
- 애플리케이션 개발자와 데이터 사이언티스트를 위해 서로 다른 플랫폼을 갖추는 것 역시 협업을 복잡하게 만들고 개발 속도를 저하시킬 수 있습니다.
- 특히 별도의 개발 및 프로덕션 플랫폼을 사용하는 경우 규모에 맞게 지능형 애플리케이션을 배포하는 것이 어려울 수 있습니다.
Red Hat® OpenShift® Data Science는 데이터 사이언티스트와 개발자에게 지능형 애플리케이션을 빌드하고 배포할 수 있는 강력한 AI/ML 플랫폼을 제공하는 관리형 클라우드 서비스 오퍼링입니다. 조직은 하나의 공통된 플랫폼에서 원하는 툴을 실험하고, 협업하고, 시장 출시 속도를 가속화할 수 있습니다. OpenShift Data Science는 데이터 사이언티스트와 개발자가 원하는 셀프 서비스 환경과 엔터프라이즈 IT 팀이 요구하는 신뢰성을 결합합니다.
신뢰할 수 있는 기반을 갖추게 되면 라이프사이클 전반에서 마찰이 줄어들게 됩니다. OpenShift Data Science는 강력한 플랫폼, 널리 사용되는 인증 툴을 갖춘 광범위한 에코시스템, 그리고 모델을 프로덕션에 배포하기 위한 익숙한 워크플로우를 제공합니다. 이러한 장점 덕분에 팀은 협업 시 마찰을 줄이고 지능형 애플리케이션을 더욱 효율적으로 시장에 출시하여 궁극적으로 비즈니스에 더 큰 가치를 제공할 수 있습니다.
신속한 개발, 교육, 테스트, 배포
OpenShift Data Science는 Open Data Hub 프로젝트와 Operate First 커뮤니티를 기반으로 합니다. Open Data Hub는 Red Hat OpenShift에서 Apache Kafka와 Kubeflow와 같은 업스트림 노력을 통해 AI/ML 플랫폼을 보여줍니다. Operate First는 운영에 오픈소스 개념을 적용하여 개발자와 운영자가 독점 종속성(Lock-In)없이 운영 효율성을 실현할 수 있도록 지원합니다. OpenShift Data Science는 Amazon Web Services(AWS)에서 독립 소프트웨어 벤더(ISV)를 통해 관리되며 전체 지원되는 클라우드 서비스를 통해 Open Data Hub 툴의 하위 세트를 제공합니다.
원하는 툴로 실험
데이터 사이언티스트는 OpenShift Data Science를 통해 비즈니스에 관한 인사이트를 얻기 위한 새로운 방법을 실험하고 탐색할 수 있습니다. 데이터 사이언티스트는 전체 관리형 클라우드 서비스로 머신 러닝 모델을 배포하기 전에 개발, 교육, 테스트할 수 있습니다. 팀은 통합 경험을 통해 제공되는 고급 툴에 액세스할 수 있습니다. 데이터 사이언티스트는 규범적인 툴체인으로 인한 부담에서 벗어나 익숙한 툴을 사용하거나 점차 성장하는 기술 파트너 에코시스템에 액세스하여 더욱 심층적인 AI/ML 전문성을 쌓을 수 있습니다. IT 팀이 필요한 리소스를 프로비저닝할 때까지 기다리지 않아도 IT 티켓 대신 클릭 한 번으로 온디맨드 인프라를 확보할 수 있습니다.
공통 플랫폼에서 협업
OpenShift Data Science는 머신 러닝 워크로드와 개발 워크플로우를 위해 설계된 오픈소스 아키텍처를 기반으로 구축되었습니다. 데이터 사이언스와 DevOps의 격차를 좁혀 프로덕션으로 진행하는 과정에서 발생할 수 있는 핸드오프로 인한 번거로움을 줄입니다. 데이터 사이언티스트는 Jupyter Notebook을 통해 실시간으로 협업합니다. 개발자는 컨테이너 지원 모델을 지능형 애플리케이션으로 마찰 없이 통합합니다. IT 팀은 악성 클라우드 플랫폼 계정을 추적할 필요가 없어 거버넌스에 대해 크게 우려하지 않아도 됩니다.
지능형 애플리케이션의 시장 출시 속도 향상
OpenShift Data Science는 공유되고 일관된 플랫폼에서 머신 러닝 모델을 초기 파일럿부터 지능형 애플리케이션으로 더욱 빠르게 개발할 수 있도록 합니다. 데이터 사이언티스트는 원하는 툴과 셀프 서비스 인프라에 액세스하여 더욱 빠르게 시작할 수 있습니다. 소프트웨어 파트너 에코시스템을 통해 모든 머신 러닝 라이프사이클 단계와 더욱 심도 있는 AI 기능을 연결하여 특히 AI/ML 전문성을 갖춘 광범위한 인증 툴을 제공합니다. 하이브리드 클라우드 환경에 모델을 배포하여 필요한 모든 위치에서 상용 클라우드 종속성 없이 워크로드를 실행할 수 있는 유연성을 확보할 수 있습니다.
OpenShift Data Science
그림 1은 모델 운영 라이프사이클이 공통 플랫폼인 OpenShift Data Science 초기 오퍼링과 어떻게 통합되는지를 보여줍니다. 이 클라우드 서비스는 Red Hat OpenShift Dedicated (on AWS) 및 Red Hat OpenShift Service on AWS에서 사용할 수 있습니다. 또한 ISV 인증 소프트웨어를 통해 향상된 역량과 협업 기능을 경험할 수 있는 기회와 함께 Red Hat 관리형 서비스로서 코어 데이터 사이언스 워크플로우를 제공합니다. 모델은 OpenShift 클라우드 서비스에서 호스팅되거나 통합을 위해 지능형 애플리케이션으로 내보내집니다.
주요 내용
- 인프라에 대한 걱정 없이 원하는 툴을 사용하여 개발
- 마찰을 줄이고 하나의 공통 플랫폼에서 협업하여 데이터 사이언티스트, 개발자, IT 운영 팀을 통합
- 지능형 애플리케이션 제공 속도를 높이고 시장 출시 시간 단축
- 광범위한 파트너 에코시스템에서 애플리케이션과 서비스를 선택할 수 있도록 하여 데이터 사이언티스트의 역량 강화
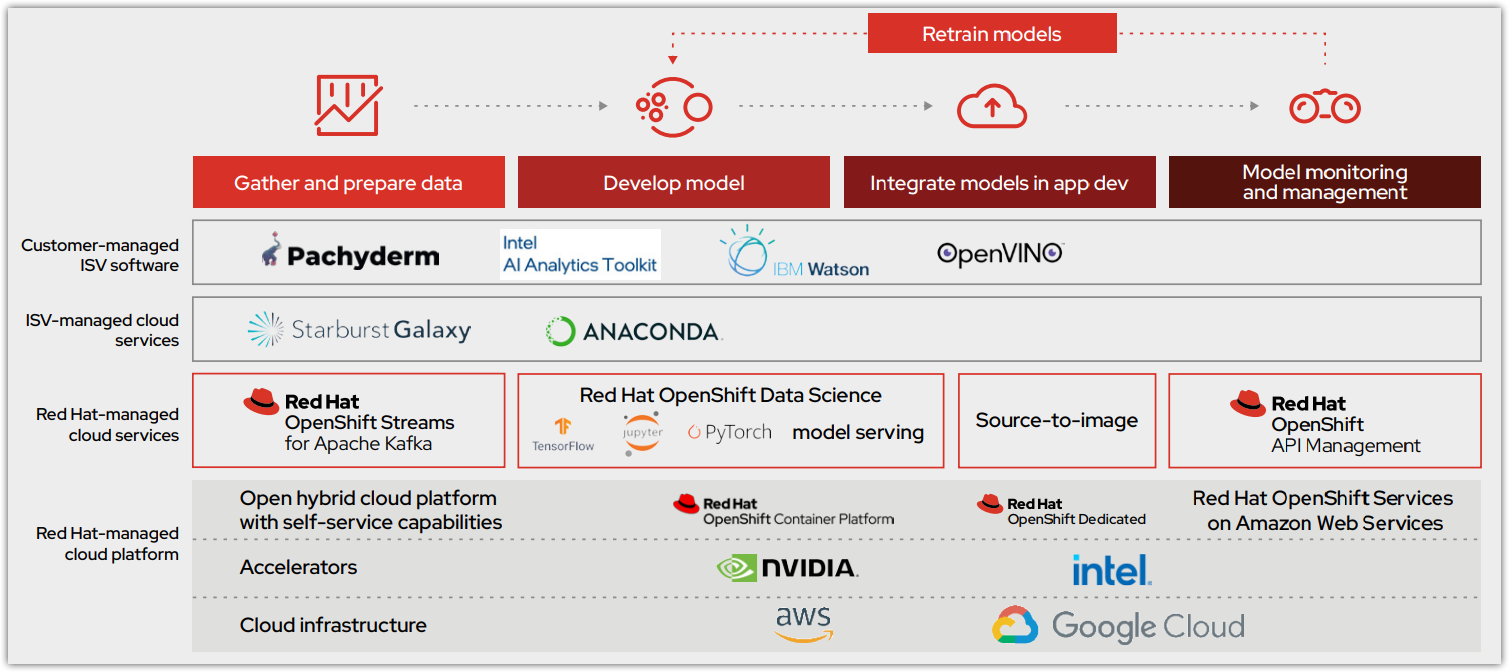
OpenShift Data Science가 제공하는 다음과 같은 핵심 툴과 기능으로 탄탄한 토대를 구축할 수 있습니다.
- Jupyter Notebooks. 데이터 사이언티스트는 TensorFlow와 PyTorch를 포함하여 핵심 AI/ML 라이브러리와 프레임워크에 대한 액세스로 JupyterLab에서 탐색적 데이터 사이언스를 수행할 수 있습니다.
- S2I(Source-to-Image). S2I를 통해 지능형 애플리케이션으로의 통합을 위한 엔드포인트로서 모델을 게시하고, 소스 notebook에 대한 변경 사항을 바탕으로 재구축 및 재배포할 수 있습니다.
- 최적화된 추론. 딥러닝 모델을 최적화된 추론 엔진으로 전환하여 실험을 가속화할 수 있습니다.
Red Hat은 서비스의 일환으로 Tensorflow와 PyTorch를 위한 Jupyter Notebook 이미지를 제공하여 팀이 처음부터 시작하지 않고도 이와 같은 강력한 기술을 손쉽게 수용하도록 도와줍니다. Jupyter Spawner는 일관성과 유연성을 위해 조직의 사용자 정의 이미지를 데이터 사이언스 팀에 배포하여 선호하는 라이브러리, 툴, 언어를 통합할 수 있습니다. 또한 서비스에는 JupyterLab에 대한 Git 플러그인이 포함되어 있어 JupyterLab 인터페이스에서 직접 Git와 통합하는 데 걸리는 시간이 줄어듭니다. 서비스의 일환으로 제공되는 기타 공통 분석 패키지는 운영을 간소화하고 Pandas, scikit-learn, NumPy와 같이 프로젝트에 적합한 툴로 더욱 쉽게 시작할 수 있도록 도와줍니다.
Red Hat은 관리형 클라우드 서비스로서 기본 OpenShift 애플리케이션 플랫폼과 OpenShift Data Science 서비스를 위한 SRE(사이트 신뢰성 엔지니어링) 지원을 제공합니다. 이와 같은 지원을 통해 조직은 기본 플랫폼이 아닌 비즈니스 분석에 집중할 수 있습니다. Red Hat은 기본 Red Hat OpenShift 관리형 클라우드 서비스 환경을 비롯하여 Red Hat OpenShift Data Science 서비스에 대한 고가용성을 유지합니다. 모든 업데이트, 업그레이드, 호환성이 서비스의 일부로 관리되어 분석 툴 간의 복잡할 수 있는 호환성 매트릭스를 추적할 필요가 없습니다.
완전한 모델 라이프사이클을 위한 툴
OpenShift Data Science는 서비스와 소프트웨어를 제공하여 조직이 성공적으로 모델을 배포하고 이를 프로덕션으로 이동시킬 수 있도록 합니다(그림 2). OpenShift Data Science와 더불어 이 프로세스는 Red Hat OpenShift API Management와 통합됩니다.
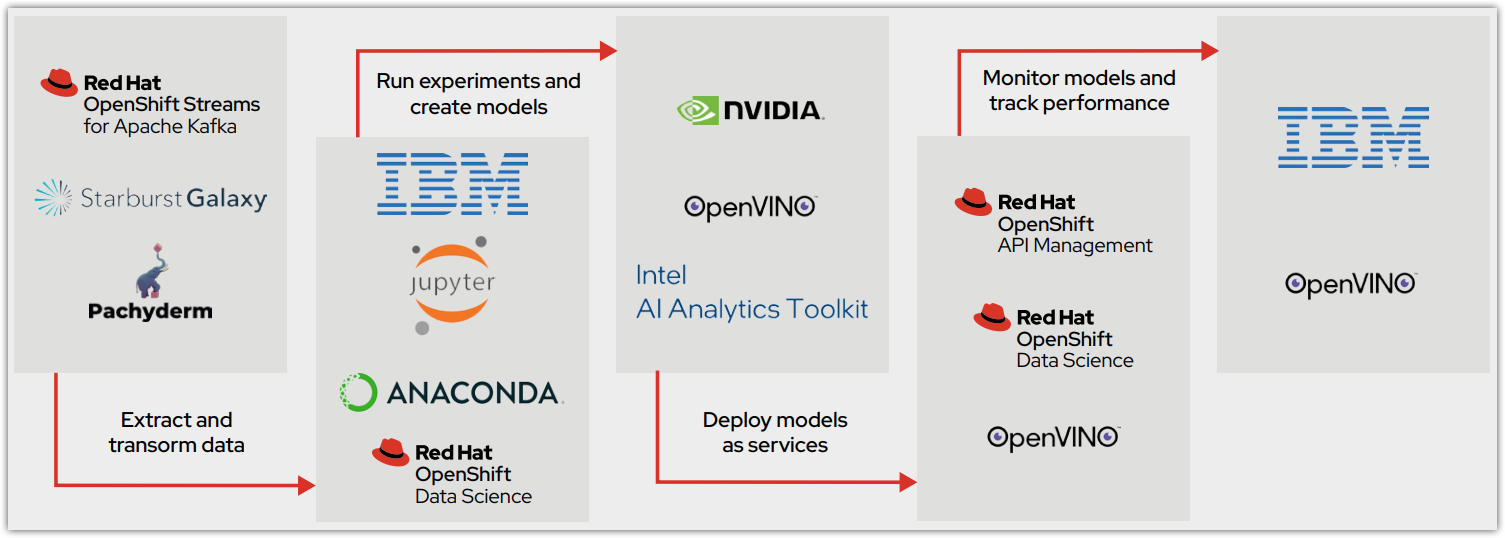
Red Hat OpenShift Data Science 대시보드는 원활한 도입을 위해 모든 애플리케이션과 도큐멘테이션을 찾고 액세스할 수 있는 중앙 위치를 제공합니다. 시작하는 방법에 관한 스마트 튜토리얼은 공통 구성 요소와 통합 파트너 소프트웨어에 대한 모범 사례 가이드를 제공하며, 이는 대시보드에서 직접 이용할 수 있어 데이터 사이언티스트가 더욱 빠르게 학습하고 시작할 수 있도록 도와줍니다. 다음 섹션에서는 Red Hat OpenShift Data Science에 포함된 주요 분석 툴에 대해 설명합니다.
Starburst
Starburst는 팀이 데이터를 활용하여 쉽고 빠르게 비즈니스 기능을 개선하도록 하여 분석을 가속화합니다. 셀프 관리형 제품 또는 전체 관리형 서비스로 제공되는 Starburst는 데이터 액세스를 대중화하여 데이터 소비자에게 더욱 포괄적인 인사이트를 제공합니다. Starburst는 주요 대량 병렬 처리(Massively Parallel Processing, MPP) SQL 엔진인 오픈소스 Trino(이전 명칭: PrestoSQL)를 기반으로 구축되었습니다. Trino 전문가들과 Presto 창시자들이 구축하고 운영하는 Starburst는 데이터를 이동하지 않고도 위치와 관계 없이 다양한 데이터 세트를 검토할 수 있는 자유를 제공합니다.
Starburst는 Red Hat OpenShift가 제공하는 확장 가능한 클라우드 스토리지와 컴퓨팅 서비스와 통합되어 더욱 안정적이고 보안에 중점을 둔 효율적이고 경제적인 방법으로 모든 엔터프라이즈 데이터를 쿼리합니다. 장점은 다음과 같습니다.
- 자동화. Starburst와 Red Hat OpenShift 오퍼레이터는 클러스터의 자동 구성, 자동 튜닝, 자동 관리를 제공합니다.
- 고가용성과 단계적인 스케일 다운 Red Hat OpenShift 로드 밸런서는 Trino 코디네이터와 같은 서비스를 상시 가동 상태로 유지할 수 있습니다.
- 유연한 확장성. Red Hat OpenShift는 Trino 작업자 클러스터를 쿼리 로드에 따라 자동으로 확장할 수 있습니다.

Anaconda Commercial Edition
Anaconda Commercial Edition은 Red Hat OpenShift Data Sciences 대시보드에서 직접 사용할 수 있는 사전 구축된 Jupyter 이미지와 함께 Jupyter 프로젝트에 사용할 수 있는 광범위한 데이터 사이언스 패키지에 대한 엄선된 액세스 권한을 제공합니다. Anaconda Commercial Edition은 조직이 다음과 같이 상업적인 사용을 위해 최적화된 세계적으로 널리 사용되는 오픈소스 패키지 배포판과 관리 경험에 액세스할 수 있도록 합니다.
- 오픈소스 혁신. Anaconda 프리미엄 리포지토리에서 이용할 수 있는 Anaconda가 엄선한 7,500개 이상의 데이터 사이언스 및 ML 패키지.
- 콘텐츠 신뢰 기능. Conda 서명 인증과 같이 데이터 사이언스와 ML 파이프라인에서 취약점과 신뢰할 수 없는 소프트웨어를 제거하도록 돕는 기능.
- 프로덕션 워크플로우와 관련하여 신뢰할 수 있는 가동 시간 서비스 수준 계약(SLA)과 지원을 통한 안정성.
- Anaconda 서비스 약관에 따른 상업적 사용에 대한 완벽한 컴플라이언스.
IBM Watson Studio
IBM Watson Studio1는 Watson Machine Learning과 Watson OpenScale로 AI 모델을 규모에 따라 빌드, 실행, 관리할 수 있도록 합니다. 이 플랫폼은 코드 기반 데이터 사이언스와 시각적 데이터 사이언스를 위해 PyTorch, TensorFlow, scikit-learn과 같은 오픈소스 프레임워크와 IBM 및 IBM 에코시스템 툴을 결합합니다. 또한 Jupyter Notebooks, JupyterLab, 커맨드라인 인터페이스(CLI), Python 언어와 연동됩니다.
IBM Watson은 원칙에서 사례까지 AI를 운영화하여 신뢰성을 높입니다. 투명한 프로세스는 AI 기반 의사 결정에 대한 인사이트를 제공합니다. IBM Watson은 규제가 강력한 산업 전반에서 데이터 프라이버시, 컴플라이언스, 보안을 실현하고, 책임 있는 AI 사용을 촉진하는 다양한 개방형 에코시스템을 지원합니다. IBM Watson Studio는 다음을 제공합니다.
- 자동으로 모델 파이프라인을 구축하고, 데이터를 준비하고, 모델 유형을 선택하고, 모델 파이프라인을 생성하여 순위를 부여하는 AutoAI 및 AutoML
- 그래픽 플로우 에디터로 데이터를 정리하고 형성하는 고급 데이터 세분화
- IBM SPSS Modeler를 통한 통합 시각적 툴링으로 데이터를 신속하게 준비하고 시각적으로 모델 개발
- 최적화된 파이프라인으로 빠르게 실험을 구축하는 모델 교육 및 개발
- 예측적 모델과 규범적 모델을 결합하는 임베디드 의사 결정 최적화 기능
- 모델의 품질, 공정성, 드리프트 메트릭스 관리 및 모니터링
- Python Jupyter Notebook으로 모델 내보내기

Pachyderm
조직은 노트북 실험부터 중요한 엔터프라이즈 배포까지 모든 것을 용이하게 지원하는 데이터 관리 솔루션을 필요로 합니다. Pachyderm은 자동 데이터 버전 관리를 통해 확보한 데이터 계보를 통해 데이터 사이언스 팀이 컨테이너화된 데이터 중심의 ML 파이프라인을 구축하고 확장하도록 합니다. 실제 데이터 사이언스 문제를 해결하도록 엔지니어링된 Pachyderm은 팀이 ML 라이프사이클을 자동화하고 확장할 수 있도록 데이터 기반을 제공하는 동시에 재현 가능성을 보장합니다. 비정형 데이터에서 데이터 웨어하우스, 자연어 처리, 동영상 및 이미지 ETL, 금융 서비스, 생명과학에 이르는 광범위한 활용 사례를 통해 Pachyderm은 다음 기능을 제공합니다.
- 팀이 모든 데이터 변경 사항을 높은 성능으로 추적할 수 있는 방법을 제공하는 자동화된 데이터 버전 관리
- 데이터 처리 속도를 높이는 동시에 컴퓨팅 비용을 낮추는 데이터 중심의 컨테이너화된 파이프라인
- ML 라이프사이클 내 모든 활동과 자산에 대한 고정된 기록을 제공하는 변경 불가능한 데이터 계보
- 방향성 비순환 그래프(Directed Acyclic Graph, DAG)의 직관적인 시각화를 제공하고 디버깅과 재현 가능성을 지원하는 Pachyderm Console
- Pachyderm의 JupyterLab Mount Extension을 통해 Pachyderm 버전 관리 데이터에 대한 포인트 앤 클릭(point-and-click) 인터페이스를 제공하는 Jupyter Notebook 지원
- 조직 내 다양한 팀 전반에서 규모에 따른 Pachyderm 배포와 관리를 위한 강력한 툴을 갖춘 엔터프라이즈 관리

NVIDIA의 데이터 사이언스 가속
확장 가능한 데이터 프로세싱, 데이터 분석, 머신 러닝 교육, 추론은 모두 고도로 리소스 집약적인 컴퓨팅 태스크를 나타냅니다. NVIDIA 소프트웨어는 GPU의 병렬 처리 기능을 활용하여 엔드 투 엔드 데이터 사이언스의 모든 측면을 가속화할 수 있습니다. 온프레미스 GPU 리소스를 확장하거나 이를 사용하도록 쿠버네티스 프로비저닝을 구성하더라도 데이터 사이언티스트가 데이터에서 가치를 추출하는 작업을 방해해서는 안 됩니다.
다양한 조직이 머신 러닝과 다양한 서비스를 위해 이미 NVIDIA 솔루션을 활용하고 있습니다. OpenShift Data Science는 GPU 지원 하드웨어를 구성하는 복잡성을 줄여 리소스 집약적인 데이터 사이언스 실험을 가속화합니다. OpenShift Data Science를 통해 조직은 NVIDIA GPU로 구동되는 Amazon Elastic Computing(EC2) 인스턴스를 온디맨드로 활용하여 필요에 따라 컴퓨팅 리소스를 확장 또는 축소할 수 있습니다.

Intel OpenVINO 툴킷
OpenVINO 툴킷의 Intel 배포판은 Intel 플랫폼상에서 고성능 DL 추론 애플리케이션의 개발과 배포를 가속화합니다. 이 툴킷은 포함되어 있는 모델 최적화 프로그램과 런타임 및 개발 툴을 사용하여 포괄적인 AI 추론을 빌드, 최적화, 튜닝, 실행할 수 있도록 합니다.
- 빌드: 개발자는 Open Model Zoo를 사용하여 추론을 지원하도록 사전 교육되고 사전 최적화된 오픈소스 모델을 찾거나, 자체 DL 모델을 사용할 수 있습니다.
- 최적화. 모델 최적화 프로그램은 모델을 중간 표현(Intermediate Representation, IR)으로 전환하여 네트워크 토폴로지를 설명하고 모델의 가중치와 편향을 포함하는 한 쌍의 파일을 생성할 수 있습니다.
- 배포. 추론 엔진은 한 번 작성하여 어디에나 배포할 수 있는 효율성을 갖춘 여러 프로세서, 액셀러레이터, 환경에 대한 결과를 출력할 수 있습니다.

Intel® AI 분석 툴킷
Intel AI 분석 툴킷은 데이터 사이언티스트, AI 개발자, 연구자가 Intel 아키텍처에서 엔드 투 엔드 데이터 사이언스와 분석 파이프라인을 가속화하도록 익숙한 Python 툴과 프레임워크를 제공합니다. 구성 요소는 낮은 수준의 컴퓨팅 최적화를 위해 oneAPI 라이브러리를 사용합니다. 이 툴킷은 ML을 통한 사전 처리 성능을 극대화하고 효율적인 모델 개발을 위해 상호운용성을 제공합니다.
Intel AI 분석 툴킷을 사용하면 다음을 수행할 수 있습니다.
- Intel XPU에서 고성능 DL 교육을 제공하고, TensorFlow와 PyTorch를 위한 Intel 최적화 DL 프레임워크, 사전 교육된 모델, 저정밀 툴을 통해 AI 개발 워크플로우에 신속한 추론을 통합합니다.
- Intel에 최적화된 컴퓨팅 집약적인 Python 패키지, Modin, scikit-learn, XGBoost로 데이터 사전 처리와 ML 워크플로우에 대한 즉각적인 가속화를 달성합니다.
- Intel에서 직접 분석과 AI 최적화에 액세스하여 소프트웨어가 중단없이 작동하도록 합니다.
결론
OpenShift Data Science를 사용하여 조직은 지능형 애플리케이션 여정에서 실험하고 협업하며 궁극적으로 여정을 가속화할 수 있습니다. Red Hat이 관리하는 클라우드 기반의 애드온 서비스는 데이터 사이언티스트를 위한 실험을 간소화하고 가속화하며, 현대적인 컨테이너화된 AI/ML 플랫폼과 AWS의 편의성 및 확장성을 제공합니다. 개발자와 데이터 사이언티스트를 위한 셀프 서비스는 이미 엔터프라이즈 IT에서 사용하고 완전히 신뢰하는 애플리케이션 플랫폼에서의 혁신 속도를 높입니다. 컴퓨팅 접근 방식과는 달리 데이터 사이언티스트가 제한적인 툴체인 없는 툴링을 선택하여 임의적인 제약 없이 새로운 데이터 인사이트를 발견할 수 있습니다.
IBM Watson Studio와 Watson Machine Learning은 IBM의 Cloud Pak for Data 오퍼링의 일부입니다.
