
Cette année, lors du Ray Summit, nous sommes ravis de présenter la pile d'infrastructure que nous créons avec IBM Research. Elle comprend Ray et CodeFlare pour les charges de travail distribuées par l'intelligence artificielle (IA) générative. Les technologies ont été introduites dans des communautés Open Source comme Open Data Hub et développées pour faire partie de la solution Red Hat OpenShift AI, sur laquelle se basent également IBM watsonx.ai et les modèles de fondation IBM utilisés par Red Hat Ansible Automation Platform. Red Hat OpenShift AI associe une puissante suite d'outils et de technologies conçus pour simplifier, mettre à l'échelle et optimiser le processus de réglage fin et de distribution des modèles de fondation. La plateforme fournit ces outils pour régler, entraîner et déployer des modèles de manière cohérente, aussi bien sur site que dans le cloud. Nos derniers travaux offrent de nombreuses options de réglage fin et de distribution des modèles de fondation pour offrir aux spécialistes des sciences des données et des pratiques MLOps des fonctionnalités telles que l'accès en temps réel aux ressources du cluster ou la planification des charges de travail pour le traitement par lots.
Dans cet article, vous allez apprendre à régler et déployer en toute simplicité un modèle HuggingFace GPT-2 composé de 137 millions de paramètres sur un ensemble de données WikiText à l'aide de Red Hat OpenShift AI. Pour le réglage fin, nous utiliserons la pile Distributed Workloads avec le paramètre KubeRay sous-jacent pour la parallélisation, et la pile KServe/Caikit/TGIS pour le déploiement et la surveillance de notre modèle de fondation GPT-2.
La pile Distributed Workloads comprend deux composants principaux :
- KubeRay, un opérateur Kubernetes pour le déploiement et la gestion des clusters Ray distants qui exécutent des charges de travail de calcul distribuées
- CodeFlare, un opérateur Kubernetes qui déploie et gère le cycle de vie de trois composants :
- CodeFlare-SDK, un outil pour la définition et le contrôle des tâches et de l'infrastructure de calcul distribuées à distance, et qui sert à déployer un notebook
- Multi-Cluster Application Dispatcher (MCAD), un contrôleur Kubernetes pour la gestion des tâches par lots dans un environnement à un ou plusieurs clusters
- InstaScale, un outil de mise à l'échelle à la demande des ressources agrégées dans toutes les variantes OpenShift avec configuration MachineSets (autogérée ou gérée, comme Red Hat OpenShift on AWS ou Open Data Hub)

Figure 1 : interactions entre les composants et le workflow de l'utilisateur dans Distributed Workloads
Comme indiqué sur la Figure 1, l'optimisation de votre modèle de fondation avec Red Hat OpenShift AI commence par CodeFlare, un framework dynamique qui rationalise et simplifie la création, l'entraînement et le réglage des modèles. Ensuite, vous pourrez exploiter la puissance de Ray, un framework informatique distribué, en utilisant KubeRay pour répartir efficacement vos efforts de réglage fin, ce qui réduit considérablement le temps nécessaire pour optimiser les performances de votre modèle. Une fois que vous aurez défini votre charge de travail de réglage fin, MCAD mettra en file d'attente votre charge de travail Ray jusqu'à ce que les exigences en matière de ressources soient satisfaites, puis créera le cluster Ray dès qu'il sera possible de planifier l'ensemble de vos pods.
En ce qui concerne la distribution, la pile KServe/Caikit/TGIS se compose des éléments suivants :
- KServe, une définition de ressources personnalisées Kubernetes pour les modèles distribués en production qui gère le cycle de vie du déploiement de modèles
- Text Generation Inference Server (TGIS), un serveur ou un backend de distribution qui charge les modèles et fournit le moteur d'inférence
- Caikit, un ensemble d'outils/une exécution d'IA qui gère le cycle de vie du processus TGIS et fournit des points de terminaison d'inférence ainsi que des modules pour la gestion de différents types de modèles
- OpenShift Serverless (opérateur prérequis), basé sur le projet Open Source Knative qui permet aux équipes de développement de créer et déployer des applications serverless et orientées événements pour les entreprises
- OpenShift Service Mesh (opérateur prérequis), qui repose sur le projet Open Source Istio et offre une plateforme pour les données comportementales et le contrôle de l'exploitation des microservices en réseau dans un Service Mesh
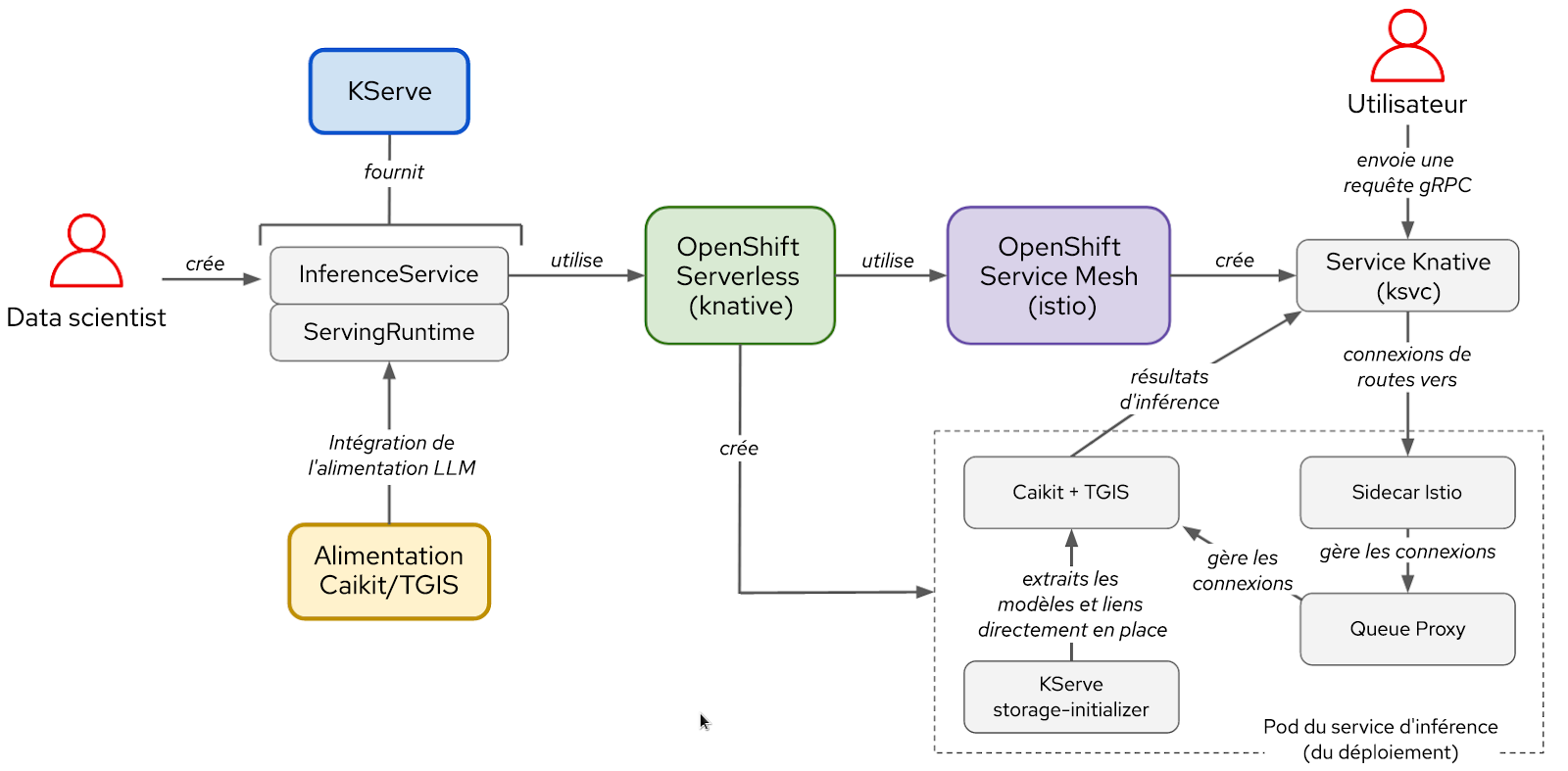
Figure 2 : interactions entre les composants et le workflow de l'utilisateur dans la pile KServe/Caikit/TGIS
Après le réglage fin du modèle, vous devrez le déployer avec l'environnement d'exécution et le backend Caikit/TGIS pour simplifier et rationaliser la mise à l'échelle et la maintenance de votre modèle. Vous utiliserez pour cela la solution KServe qui fournit une infrastructure de distribution fiable et avancée. En arrière-plan, Red Hat OpenShift Serverless (Knative) provisionnera le déploiement serverless de notre modèle et Red Hat OpenShift Service Mesh (Istio) gérera l'ensemble des flux réseau et de trafic (voir la Figure 2).
Configuration de l'environnement
Dans cette démonstration, nous partons du principe qu'un cluster OpenShift avec l'opérateur Red Hat OpenShift Data Science est installé ou ajouté en tant que module complémentaire. La démonstration peut également être exécutée avec Open Data Hub comme plateforme sous-jacente.
Pour régler votre modèle, vous devez installer l'opérateur communautaire CodeFlare disponible dans OperatorHub. L'opérateur CodeFlare installe MCAD, InstaScale, l'opérateur KubeRay et l'image de notebook CodeFlare. Des paquets tels que codeflare-sdk, pytorch et torchx sont inclus. Si vous utilisez des processeurs graphiques (GPU), vous devrez également installer les opérateurs NVIDIA GPU et Node Feature Discovery.
Pour la distribution, vous pouvez simplement exécuter ce script pour qu'il installe tous les opérateurs prérequis et l'ensemble de la pile KServe/Caikit/TGIS. Veuillez définir TARGET_OPERATOR sur rhods.
Bien que les instructions d'installation des piles Distributed Workloads et KServe/Caikit/TGIS soient plus ou moins manuelles jusqu'ici, les deux piles seront bientôt disponibles et prises en charge par Red Hat OpenShift Data Science.
Réglage fin d'un grand modèle de langage
Vous allez commencer par lancer le notebook CodeFlare à partir du tableau de bord de Red Hat OpenShift AI (voir la Figure 3) et cloner le référentiel de démonstration qui contient le notebook ainsi que d'autres fichiers nécessaires à cette démonstration.

Figure 3 : image de notebook CodeFlare affichée dans le tableau de bord OpenShift Data Science
Au début, vous devez définir les paramètres pour le type de cluster souhaité (ClusterConfiguration), comme le nom du cluster, l'espace de noms dans lequel le déployer, les ressources de processeur, de GPU et de mémoire requises ainsi que les types de machines. Vous devez également déterminer si vous souhaitez tirer parti de la fonctionnalité de mise à l'échelle automatique d'InstaScale. Si vous travaillez dans un environnement sur site, vous pouvez ignorer machine_types et définir instascale=False. Ensuite, l'objet cluster est créé et soumis à MCAD pour mettre en route le cluster Ray.
Lorsque le cluster Ray est prêt et que vous pouvez voir les détails du cluster Ray dans la commande cluster.details() du notebook, vous pouvez définir votre tâche de réglage fin en indiquant un nom, le script à exécuter, les arguments éventuels et une liste des bibliothèques requises, et la soumettre au cluster Ray que vous venez de créer. La liste d'arguments spécifie le modèle GPT-2 à utiliser et l'ensemble de données WikiText avec lequel régler le modèle. Le SDK CodeFlare vous permet de suivre l'état, les journaux et d'autres informations grâce à une interface en ligne de commande ou au tableau de bord Ray.
Une fois le réglage fin du modèle terminé, le résultat de job.status() devient SUCCEEDED et les journaux du tableau de bord Ray indiquent la fin du processus (voir la Figure 4). En utilisant 1 nœud de travail Ray qui fonctionne sur le GPU NVIDIA T4 avec 2 processeurs et 8 Go de mémoire, le réglage fin du modèle GPT-2 a pris environ 45 minutes.

Figure 4 : les journaux du tableau de bord Ray montrent la fin du réglage fin du modèle
Vous devrez ensuite créer un répertoire dans le notebook, y enregistrer le modèle, puis le télécharger dans votre environnement local pour le convertir et le charger dans un compartiment MinIO par la suite. Veuillez noter que nous utilisons un compartiment MinIO dans cette démonstration. Cependant, vous pouvez choisir un autre type de compartiment S3, une PVC ou tout autre type de stockage en fonction de vos préférences.
Distribution du grand modèle de langage
Maintenant que vous avez réglé votre modèle de fondation, il est temps de le mettre en œuvre. À partir du même notebook utilisé pour le réglage fin, vous devez créer un espace de noms dans lequel vous allez :
- déployer l'environnement d'exécution Caikit+TGIS ;
- déployer la connexion de données S3 ;
- déployer le service d'inférence qui pointe vers votre modèle situé dans un compartiment MinIO.
Un environnement d'exécution est une définition de ressource personnalisée dont le but est de créer un environnement pour le déploiement et la gestion de modèles en production. Il crée les modèles pour les pods qui peuvent charger et décharger dynamiquement des modèles de différents formats à la demande, et exposer un point d'accès de service pour les demandes d'inférence. Vous déploierez l'environnement d'exécution qui mettra à l'échelle les pods d'exécution une fois qu'un service d'inférence sera détecté. Le port 8085 sera utilisé pour l'inférence.
Un service d'inférence est un serveur qui accepte les données d'entrée, les transmet au modèle, exécute le modèle et renvoie le résultat d'inférence. Dans le service d'inférence que vous déployez, vous devez spécifier l'environnement d'exécution que vous avez déployé précédemment, activer la route directe pour l'inférence gRPC et pointer le serveur vers votre compartiment MinIO où est situé le modèle réglé.
Après avoir vérifié que le service d'inférence est prêt, vous effectuez un appel d'inférence pour demander au modèle de compléter une phrase de votre choix.
Vous venez de procéder au réglage fin d'un grand modèle de langage GPT-2 avec la pile Distributed Workloads et à sa distribution avec la pile KServe/Caikit/TGIS dans OpenShift AI.
Prochaines étapes
Nous tenons à remercier les communautés Open Data Hub et Ray pour leur soutien. Il existe bien d'autres cas d'utilisation de l'intelligence artificielle/apprentissage automatique (IA/AA) avec OpenShift AI. Si vous souhaitez en savoir plus sur les fonctionnalités de la pile CodeFlare, regardez notre vidéo de démonstration qui couvre plus en détail le SDK CodeFlare, KubeRay et MCAD.
Suivez l'intégration prochaine des opérateurs CodeFlare et KubeRay dans OpenShift Data Science, et le développement de l'interface utilisateur pour la pile KServe/Caikit/TGIS qui a été récemment lancée dans OpenShift Data Science en tant que fonction à disponibilité limitée.
À propos de l'auteur

Selbi Nuryyeva is a software engineer at Red Hat in the OpenShift AI team focusing on the Open Data Hub and Red Hat OpenShift Data Science products. In her current role, she is responsible for enabling and integrating the model serving capabilities. She previously worked on the Distributed Workloads with CodeFlare, MCAD and InstaScale and integration of the partner AI/ML services ecosystem. Selbi is originally from Turkmenistan and prior to Red Hat she graduated with a Computational Chemistry PhD degree from UCLA, where she simulated chemistry in solar panels.
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles

Programmes originaux
Histoires passionnantes de créateurs et de leaders de technologies d'entreprise
Produits
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Services cloud
- Voir tous les produits
Outils
- Formation et certification
- Mon compte
- Ressources développeurs
- Assistance client
- Calculateur de valeur Red Hat
- Red Hat Ecosystem Catalog
- Rechercher un partenaire
Essayer, acheter et vendre
Communication
- Contacter le service commercial
- Contactez notre service clientèle
- Contacter le service de formation
- Réseaux sociaux
À propos de Red Hat
Premier éditeur mondial de solutions Open Source pour les entreprises, nous fournissons des technologies Linux, cloud, de conteneurs et Kubernetes. Nous proposons des solutions stables qui aident les entreprises à jongler avec les divers environnements et plateformes, du cœur du datacenter à la périphérie du réseau.
Sélectionner une langue
Red Hat legal and privacy links
- À propos de Red Hat
- Carrières
- Événements
- Bureaux
- Contacter Red Hat
- Lire le blog Red Hat
- Diversité, équité et inclusion
- Cool Stuff Store
- Red Hat Summit