
Red Hat OpenShift Data Science : des services cloud pour l'IA/AA
Accélérez le déploiement des applications intelligentes
Dans de nombreux secteurs d'activité et entreprises, les technologies d'intelligence artificielle (IA), d'apprentissage automatique (AA) et d'apprentissage profond (AP) influent de façon considérable sur la stratégie de modernisation des applications. Les entreprises cherchent à rentabiliser au mieux leurs données et à en tirer de nouvelles informations, ce qui favorise l'expansion des applications cloud-native intelligentes et des méthodes DevOps. Cette situation inédite et audacieuse peut s'avérer complexe pour toutes les disciplines : le développement, l'exploitation, comme la science des données. Les approches traditionnelles posent différents problèmes :
- La phase de démarrage peut être intimidante, car elle implique de veiller à l'actualisation et à la cohérence de services d'applications et d'outils en rapide évolution, provisionner des ressources matérielles comme des processeurs graphiques (GPU) et mettre à l'échelle les applications intelligentes.
- Certaines plates-formes cloud très prisées offrent une évolutivité, des outils intéressants et des environnements intégrés, mais elles enferment les utilisateurs dans une dépendance avec une chaîne d'outils restreinte et des options de déploiement limitées.
- Les développeurs et les data scientists n'utilisent pas la même plateforme, ce qui freine la collaboration et le développement.
- Le déploiement d'applications intelligentes à grande échelle s'avère difficile, en particulier avec des plates-formes distinctes pour le développement et la production.
Disponible sous forme de service cloud géré, Red Hat® OpenShift® Data Science offre aux équipes de science des données et de développement une puissante plateforme d'IA/AA pour la création et le déploiement d'applications intelligentes. Les entreprises peuvent expérimenter avec un vaste choix d'outils sur cette plateforme unique qui facilite la collaboration et permet d'écourter le délai de mise sur le marché. Le service OpenShift Data Science associe l'environnement en libre-service dont ont besoin les data scientists et les développeurs à la fiabilité indispensable au service informatique.
Poser des bases solides permet de diminuer le nombre de problèmes tout au long du cycle de vie. Robuste, la plateforme OpenShift Data Science inclut de nombreux outils certifiés fréquemment utilisés et des workflows déjà connus des équipes pour le déploiement en production des modèles. Grâce à tous ces avantages, les équipes peuvent collaborer de façon plus fluide et distribuer plus efficacement les applications intelligentes, avec à la clé une valeur supérieure pour l'entreprise.
Écourtez les temps de développement, entraînement, test et déploiement
Le service OpenShift Data Science repose sur le projet communautaire Open Data Hub ainsi que l'initiative Operate First. Open Data Hub est un modèle pour la création d'une plateforme d'IA/AA sur Red Hat OpenShift qui découle de projets en amont tels que Apache Kafka et Kubeflow. L'initiative Operate First met les technologies Open Source au service de la production en permettant aux équipes de développement et d'exploitation de collaborer dans un souci d'excellence opérationnelle, sans aucune dépendance vis-à-vis de solutions propriétaires. OpenShift Data Science intègre une partie des outils d'Open Data Hub sous la forme d'un service cloud entièrement pris en charge et géré sur Amazon Web Services (AWS). Il est également possible d'ajouter d'autres offres d'éditeurs de logiciels indépendants (ISV).
Un vaste choix d'outils pour expérimenter
Avec OpenShift Data Science, les data scientists expérimentent et découvrent de nouvelles façons d'exploiter les informations. Ce service cloud entièrement géré leur permet de développer, d'entraîner et de tester des modèles d'apprentissage automatique avant leur déploiement, au moyen d'outils avancés directement intégrés. En plus des outils qu'ils maîtrisent déjà, les data scientists ont accès à une expertise plus poussée en matière d'IA/AA à travers un panel d'offres de partenaires technologiques toujours plus riche, sans la contrainte d'utiliser une chaîne d'outils précise. Plus besoin d'envoyer une demande au service informatique et d'attendre le provisionnement des ressources requises : l'infrastructure est disponible sur demande, d'un simple clic.
Une plateforme collaborative commune
L'architecture Open Source du service OpenShift Data Science, spécialement conçue pour les charges de travail d'AA et les workflows de développement, rapproche les équipes de science des données et de DevOps. Elle évite ainsi de nombreux transferts d'informations jusqu'à la mise en production. Les data scientists collaborent en temps réel sur des notebooks Jupyter. Les équipes de développement intègrent plus facilement les modèles adaptés aux conteneurs dans leurs applications intelligentes. Et la gouvernance ne pose plus souci au service informatique, qui n'a pas besoin de surveiller les comptes non autorisés sur la plateforme cloud.
Les applications intelligentes plus vite sur le marché
Le service OpenShift Data Science accélère le déploiement des modèles d'AA issus des projets pilotes dans les applications intelligentes, le tout sur une plateforme cohérente et partagée. Les data scientists peuvent se mettre à l'œuvre très rapidement avec les outils de leur choix et accéder en libre-service à l'infrastructure. À chaque étape du cycle de l'AA, ils bénéficient de nouvelles capacités d'IA grâce aux nombreux logiciels certifiés et spécialisés de l'écosystème d'éditeurs partenaires. Au final, vous pouvez déployer vos modèles dans le cloud hybride et exécuter vos charges de travail dans l'environnement qui vous convient, sans jamais dépendre d'une solution cloud commerciale.
OpenShift Data Science
La Figure 1 montre comment le cycle de vie des modèles s'intègre à l'offre initiale de plateforme commune OpenShift Data Science. Disponible pour Red Hat OpenShift Dedicated (sur AWS) et Red Hat OpenShift Service on AWS, ce service cloud géré par Red Hat fournit un workflow de science des données de base, avec en plus la possibilité d'augmenter ses capacités et de renforcer la collaboration à l'aide de logiciels indépendants certifiés. Les modèles sont soit hébergés sur le service cloud OpenShift, soit exportés pour une intégration à une application intelligente.
Avantages clés
- Développez avec les outils de votre choix sans vous soucier de l'infrastructure.
- Facilitez la collaboration entre les équipes informatiques, de science des données et de développement grâce à une plateforme commune.
- Accélérez la distribution des applications intelligentes et leur mise sur le marché.
- Donnez plus de moyens aux data scientists en les laissant libres de choisir leurs applications et services auprès d'un vaste écosystème de partenaires.
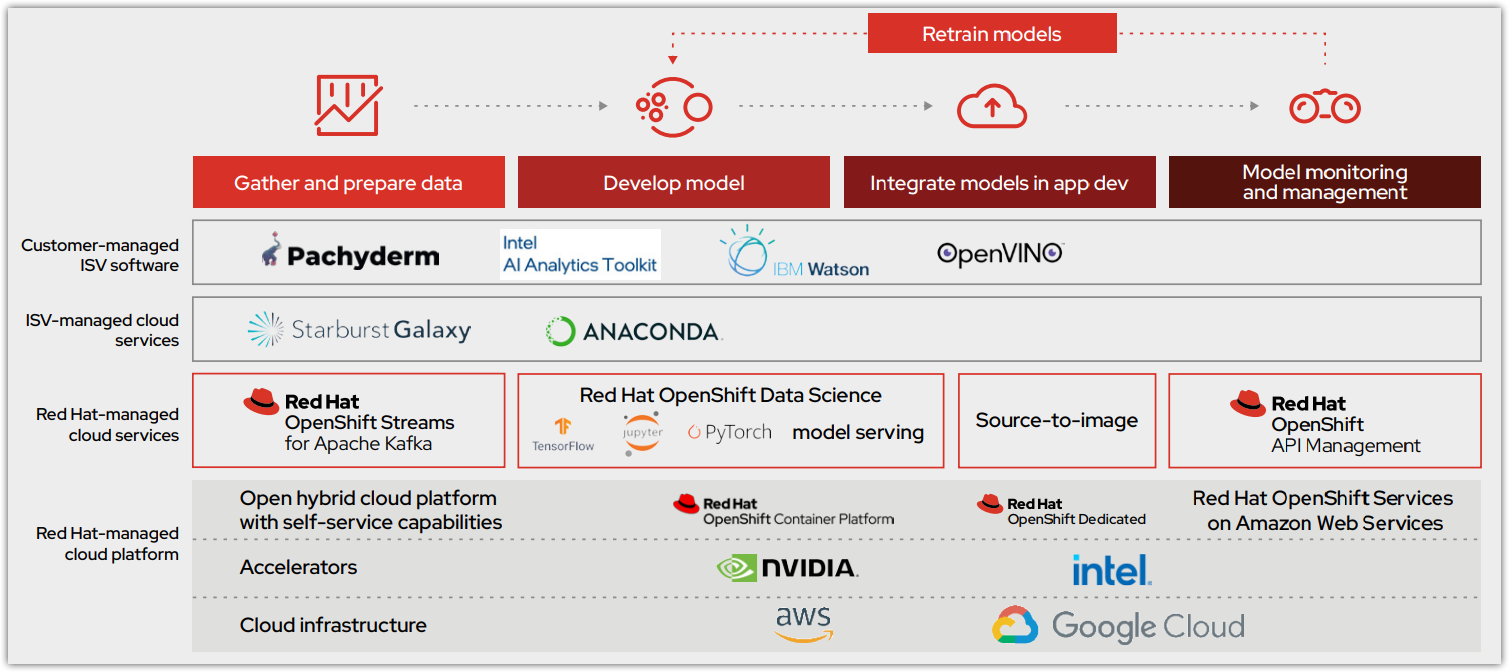
Les outils et fonctionnalités essentiels compris avec le service OpenShift Data Science forment une base solide :
- Notebooks Jupyter. Il est possible de mener des travaux de science des données exploratoires dans JupyterLab en accédant aux principaux frameworks et bibliothèques d'IA/AA, notamment TensorFlow et PyTorch.
- Déploiement S2I (source-to-image). Les modèles peuvent être publiés comme points de terminaison à intégrer à des applications intelligentes, puis recréés et redéployés en fonction des modifications apportées au notebook source.
- Optimisation des inférences. Pour accélérer les expériences, les modèles d'AP peuvent être convertis en moteurs d'inférences optimisées.
Dans le cadre du service, Red Hat fournit des images de notebook Jupyter pour Tensorflow et PyTorch, ce qui évite de partir de zéro et simplifie l'adoption de ces puissantes technologies. Pour plus de cohérence et de flexibilité, le spawner Jupyter peut fournir aux data scientists des images personnalisées qui intègrent leurs bibliothèques, outils et langages préférés. Il est aussi possible d'utiliser Git directement depuis l'interface JupyterLab via un plug-in dédié. Autres composants également inclus dans le service : des paquets d'analyse courants pour simplifier l'exploitation et lancer son projet plus aisément grâce aux bons outils, notamment Pandas, scikit-learn et NumPy.
Le service cloud géré de Red Hat s'accompagne d'une assistance en ingénierie de la fiabilité des sites (SRE) valable pour OpenShift, la plateforme d'applications sous-jacente, et le service OpenShift Data Science. Grâce à cette assistance, vous vous concentrez sur les analyses métier, sans vous soucier de la plateforme. Red Hat assure la haute disponibilité du service Red Hat OpenShift Data Science, ainsi que de l'environnement de services cloud gérés Red Hat OpenShift dont celui-ci dépend. La gestion intégrée des mises à jour, des mises à niveau et de la compatibilité évite d'avoir à suivre des matrices de compatibilité complexes entre les différents outils d'analyse.
Des outils pour le cycle de vie complet du modèle
OpenShift Data Science fournit aux entreprises les services et les logiciels nécessaires pour le déploiement et la mise en production de leurs modèles (Figure 2), un processus qui est également intégré à Red Hat OpenShift API Management.
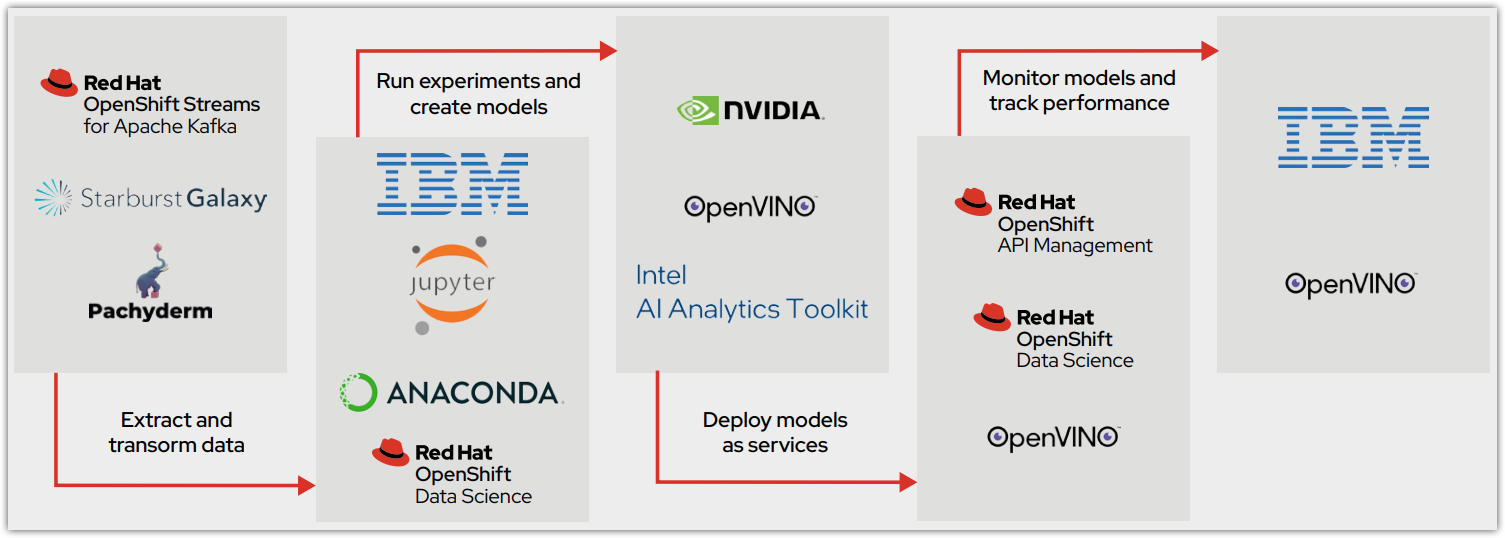
De prise en main facile, le tableau de bord Red Hat OpenShift Data Science centralise l'accès à l'ensemble des applications et supports de documentation. Des tutoriels de démarrage, directement disponibles sur le tableau de bord, délivrent les meilleures pratiques concernant les composants et les logiciels partenaires intégrés les plus utilisés. Ainsi, les data scientists se forment et sont opérationnels plus vite. Vous trouverez ci-dessous une description des principaux outils d'analyse fournis avec Red Hat OpenShift Data Science.
Starburst
Starburst accélère les analyses grâce à une solution simple et rapide qui permet de tirer parti des données pour améliorer le fonctionnement de l'entreprise. Disponible en tant que logiciel autogéré ou service entièrement géré, Starburst démocratise l'accès aux données et fournit des informations plus complètes aux utilisateurs des données. Il est basé sur l'outil Open Source Trino (anciennement PrestoSQL), une référence dans le domaine des moteurs SQL à traitement massivement parallèle (MPP). Cette offre conçue et gérée par les spécialistes de Trino et les créateurs de Presto permet d'interroger des ensembles de données très variés, dans n'importe quel environnement, sans les déplacer.
Fonctionnant en synergie avec les services évolutifs de calcul et de stockage dans le cloud de Red Hat OpenShift, Starburst apporte des performances supérieures en matière de stabilité, sécurité, efficacité et coûts. Exemples d'avantages :
- Automatisation. Avec Starburst et les opérateurs Red Hat OpenShift, les clusters sont capables de s'autoconfigurer, s'autorégler et s'autogérer.
- Haute disponibilité et arrêt de type « graceful ». L'équilibreur de charge de Red Hat OpenShift peut maintenir actifs des services comme le coordinateur Trino.
- Évolutivité. Red Hat OpenShift met à l'échelle le cluster de calcul Trino en fonction de la charge d'interrogation, de façon automatique.

Anaconda Commercial Edition
Anaconda Commercial Edition donne accès à une sélection complète de paquets de science des données compatibles avec les projets Jupyter, ainsi qu'à des images Jupyter prédéfinies disponibles depuis le tableau de bord Red Hat OpenShift Data Science. Il s'agit de l'expérience de gestion et de distribution de paquets Open Source la plus utilisée au monde, optimisée pour un usage commercial. Ses avantages pour les entreprises :
- Soutient les innovations Open Source, avec un référentiel premium de plus de 7 500 paquets d'AA et de science des données soigneusement sélectionnés par Anaconda.
- Inclut des fonctions améliorant la fiabilité des contenus (la vérification des signatures Conda, par exemple) afin de se prémunir contre les vulnérabilités et les logiciels peu fiables dans les pipelines d'AA et de science des données.
- Rassure grâce à des contrats de niveau de service sur la disponibilité et à la prise en charge des workflows de production.
- Parfaitement adapté à une utilisation commerciale régie par les conditions de service Anaconda.
IBM Watson Studio
IBM Watson Studio1 permet de créer, d'exécuter et de gérer des modèles d'IA à l'aide des services Watson Machine Learning et Watson OpenScale. Cette plateforme combine des frameworks Open Source (PyTorch, TensorFlow et scikit-learn avec IBM) et les outils de son écosystème pour la science des données visuelle et basée sur le code. Elle est compatible avec les notebooks Jupyter, JupyterLab, les interfaces en ligne de commande et les langages Python.
Les produits IBM Watson aident à mettre en production les modèles l'IA en toute confiance. Des processus transparents permettent de mieux comprendre les décisions basées sur l'IA. IBM Watson apporte sécurité, conformité et confidentialité des données dans les secteurs très réglementés, et il facilite la mise en place d'un écosystème diversifié et ouvert promouvant une utilisation responsable de l'IA. IBM Watson Studio offre les fonctions suivantes :
- AutoAI et AutoML pour l'automatisation des tâches de création des pipelines de modèles, préparation des données et sélection des types de modèles, et génération et classement de ces pipelines
- Prétraitement avancé permettant le nettoyage et la mise en forme des données dans un éditeur de flux graphique
- Intégration d'outils visuels via IBM SPSS Modeler pour la préparation rapide des données et le développement visuel des modèles
- Développement et entraînement de modèles avec des pipelines optimisés qui accélèrent les expérimentations
- Optimisation des décisions en vue de combiner modèles prédictifs et normatifs
- Gestion des modèles et suivi d'indicateurs de mesure (qualité, équité, écarts)
- Exportation des modèles au format notebook Jupyter pour Python

Pachyderm
Les professionnels ont besoin de solutions de gestion des données qui facilitent l'ensemble du processus, des expérimentations menées individuellement aux déploiements importants dans l'entreprise. Avec Pachyderm, les data scientists peuvent créer des pipelines d'AA basés sur des données et en conteneurs. De plus, un système de gestion automatique des versions garantit le lignage des données. Spécialement conçu pour résoudre les problèmes concrets liés à la science des données, Pachyderm offre les bases nécessaires pour l'automatisation et la mise à l'échelle du cycle de vie de l'AA, avec une reproductibilité assurée. Cette solution convient pour de nombreux cas d'utilisation (données non structurées, entrepôts de données, traitement du langage naturel, processus ETL pour les vidéos et les images, services financiers, sciences de la vie…) et offre les capacités suivantes :
- Gestion automatique des versions pour un suivi hautes performances de toutes les modifications apportées aux données
- Pipelines conteneurisés basés sur des données qui accélèrent le traitement des données et réduisent les coûts de calcul
- Lignage des données immuable permettant l'enregistrement fixe de toutes les activités et ressources du cycle d'AA
- Pachyderm Console, une interface intuitive de visualisation des graphes orientés acycliques (DAG) qui simplifie le débogage et assure la reproductibilité
- Prise en charge des notebooks Jupyter via le module JupyterLab Mount Extension qui permet d'accéder en quelques clics aux versions de données Pachyderm
- Outils robustes pour le déploiement et l'administration de Pachyderm au sein de différentes équipes dans l'entreprise

Logiciels accélérateurs NVIDIA dédiés à la science des données
Le traitement évolutif des données, l'analyse des données, l'entraînement des modèles d'apprentissage automatique et l'inférence sont des tâches de calcul qui consomment énormément de ressources. NVIDIA propose des logiciels qui permettent d'accélérer tous les aspects de la science des données grâce aux capacités de traitement parallèle des GPU. Les activités de mise à l'échelle des ressources GPU sur site ou de configuration du provisionnement de Kubernetes ne devraient pas empêcher les data scientists de se concentrer sur leur mission, à savoir générer de la valeur grâce aux données.
Certaines entreprises utilisent déjà des solutions NVIDIA pour l'apprentissage automatique et d'autres services. Le service OpenShift Data Science vient simplifier l'installation d'équipements GPU en vue d'accélérer les expérimentations de science des données gourmandes en ressources. Il est ainsi possible de déployer à la demande des instances Amazon Elastic Compute Cloud (EC2) équipées de GPU NVIDIA et d'ajuster les ressources de calcul selon les besoins.

Kit d'outils OpenVINO d'Intel
La distribution Intel du kit d'outils OpenVINO accélère le développement et le déploiement des applications d'inférence d'AP hautes performances sur les plateformes Intel. Comprenant des outils d'exécution et de développement, ainsi qu'un optimiseur de modèle, OpenVINO permet de créer, d'optimiser, de régler et d'exécuter tout type d'inférence dans le domaine de l'IA.
- Création. Les équipes de développement ont le choix d'utiliser leurs propres modèles d'AP ou l'un des nombreux modèles Open Source pré-entraînés et pré-optimisés du référentiel Open Model Zoo.
- Optimisation. L'outil Model Optimizer permet de convertir un modèle en une représentation intermédiaire constituée de deux fichiers, l'un décrivant la topologie du réseau et l'autre contenant les données de pondération et de biais.
- Déploiement. Avec le moteur Inference Engine, il est possible d'écrire un modèle une fois et de le déployer sur plusieurs processeurs, accélérateurs et environnements.

Kit d'outils Intel® AI Analytics
Avec le kit d'outils Intel AI Analytics, les data scientists, les développeurs d'IA et les chercheurs disposent des outils et frameworks Python qu'ils maîtrisent pour accélérer de bout en bout les pipelines d'analyse et de science des données sur les architectures Intel. Les composants utilisent les bibliothèques oneAPI pour l'optimisation des calculs de base. Ce kit maximise les performances (du prétraitement à l'AA) et offre une interopérabilité, pour un développement efficace des modèles.
Avec le kit d'outils Intel AI Analytics, vous pouvez :
- Réaliser des entraînements d'AP hautes performances sur les XPU Intel et intégrer une inférence rapide à votre workflow de développement d'IA grâce aux frameworks optimisés pour TensorFlow et PyTorch, aux modèles pré-entraînés et aux outils de faible précision
- Obtenir une accélération immédiate des workflows de prétraitement des données et d'AA grâce aux paquets Python demandant une grande puissance de calcul, à Modin, à scikit-learn et à XGBoost, optimisés pour Intel
- Accéder directement aux analyses et aux optimisations d'IA d'Intel qui garantissent l'interopérabilité continue de vos logiciels
Conclusion
Grâce au service OpenShift Data Science, les entreprises peuvent expérimenter plus facilement, collaborer davantage et, en fin de compte, accélérer le déploiement de leurs applications intelligentes. Disponible sous forme de complément géré par Red Hat, ce service cloud simplifie et accélère le processus d'expérimentation des data scientists en leur apportant une plateforme conteneurisée moderne pour l'IA/AA, ainsi que la praticité et l'évolutivité d'un environnement AWS. Les capacités en libre-service permettent aux équipes de développement et de science des données d'innover à un rythme plus soutenu, sur une plateforme d'applications familière et déjà éprouvée par le service informatique. Les data scientists peuvent dégager des informations inédites des données, en utilisant la chaîne d'outils de leur choix et sans aucune restriction arbitraire, ce que ne permettent pas les approches concurrentes.
IBM Watson Studio et Watson Machine Learning font partie de l'offre Cloud Pak for Data d'IBM.
